Conceptos básicos
Entonces, ¿qué es Git en pocas palabras? Esta es una sección importante de absorber, porque si entendemos lo que es Git y los fundamentos de cómo funciona, usar Git con eficacia probablemente será mucho más fácil. A medida que aprendamos Git, debemos tratar de limpiar nuestra mente de las cosas que podamos saber acerca de otros. Al hacerlo nos ayudará a evitar confusión al usar la herramienta. Git almacena y ve la información de manera muy diferente de otros sistemas, a pesar de que la interfaz de usuario es bastante similar.
Pantallazos en lugar de diferencias
La principal diferencia entre Git y otros sistemas, es la forma en que Git ve los datos. La mayoría de los demás sistemas almacenan la información como una lista de cambios basados en archivos. Estos sistemas piensan de la información que almacenan como un conjunto de archivos y los cambios realizados en cada archivo con el tiempo.
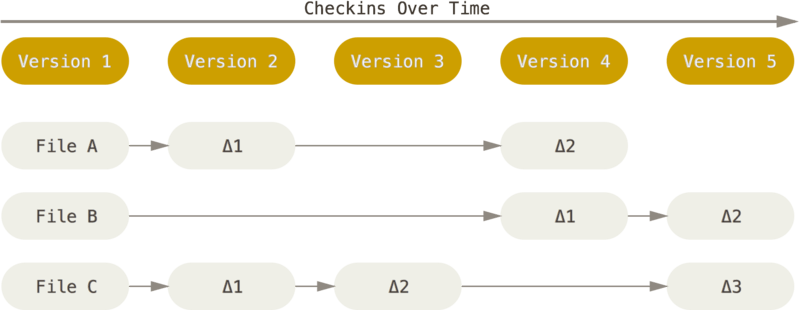
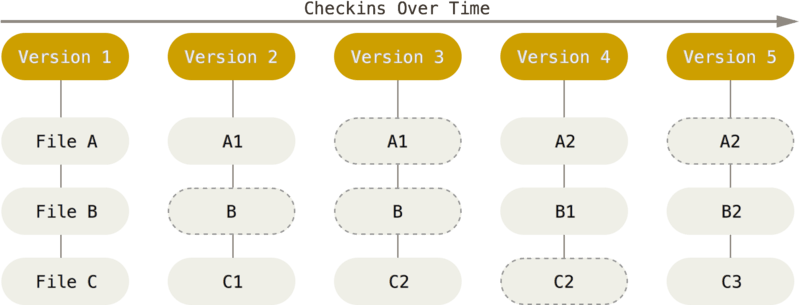
Git no ve ni almacena sus datos de esta manera. En Git los datos se manejan como un conjunto de pantallazo de un sistema de archivos en miniatura. Cada vez se guarda el estado de un proyecto en Git, básicamente se toma una fotografía de todos los archivos en ese momento y almacena una referencia a ese pantallazo. Para ser eficiente, si los archivos no han cambiado, Git no almacena el archivo de nuevo, sólo un enlace al archivo anterior que sea idéntico y ya se ha almacenado.
La mayoría de procedimientos son locales
La mayoría de las operaciones en Git sólo necesitan archivos y los recursos locales para operar, por lo general no se necesita información de otro equipo en la red.
Por ejemplo, para navegar por la historia del proyecto, Git no necesita salir al servidor para obtener la historia y mostrarla, simplemente la lee directamente desde su base de datos local. Esto significa que se ve la historia del proyecto casi al instante. Si deseamos ver los cambios introducidos entre la versión actual de un archivo y el archivo de hace un mes, Git puede buscar el archivo hace un mes y hacer un cálculo de la diferencia local, en lugar de tener que o bien pedir a un servidor remoto para hacerlo o buscar de una versión anterior del archivo desde el servidor remoto para hacerlo localmente.
Esto también significa que hay muy poco que no se puede hacer si no estamos desconectados de la red. Esto nos permite trabajar de manera remota como en un avión o un tren y guardar los cambios de manera local, hasta llegar a una conexión de red para subir los cambios al servidor.
Git por lo general solo agrega datos
La mayoría de procedimientos en Git solamente añaden datos a la base de datos. Es difícil conseguir que el sistema haga algo que no se puede deshacer o que borre datos de cualquier manera. Como en cualquier sistema de control de versiones, se pueden perder o arruinar cambios que no se han almacenado todavía; pero después de se ha guardado en Git, es muy difícil de perder, especialmente si se envía regularmente nuestra base de datos a otro repositorio.
Esto hace que el uso de Git se una alegría porque sabemos que podemos experimentar sin el peligro de dañar el sistema de manera irreversible.
Los 3 estados
Esto es de los puntos más importantes para recordar acerca de Git. Git tiene tres estados principales en que sus archivos pueden residir: modificado (modified), en espera o preparación (staged) y almacenado (committed). Modified nos dice que hemos modificado un archivo, pero no se ha guardado en la base de datos todavía. Staged es cuando seleccionamos un archivo modificado para que se almacenen los cambios en el siguiente pantallazo. Committed significa que los datos se almacenan de forma segura en la base de datos local.
Esto nos lleva a las tres secciones principales de un proyecto Git: el directorio de Git, el directorio de trabajo, y el área de espera o preparación.
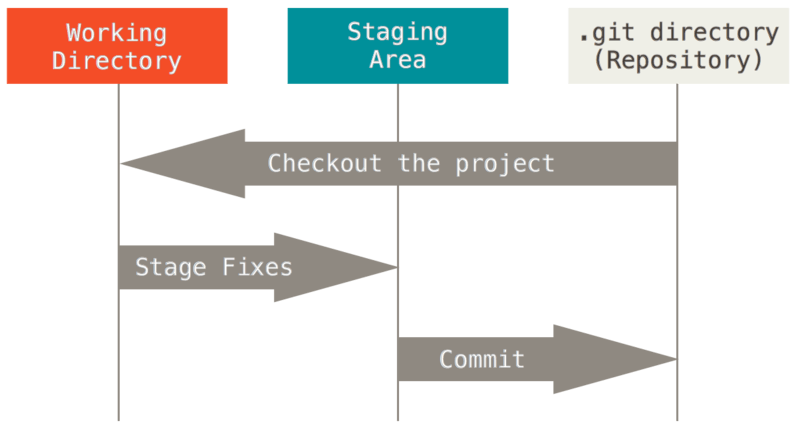
El directorio de Git es donde almacena los metadatos y la base de datos para nuestro proyecto. Esta es la parte más importante de Git, y es lo que se copia al clonar un repositorio desde otro equipo.
El directorio de trabajo es un solo una copia de una versión del proyecto. Estos archivos se extraen de la base de datos comprimida en el directorio de Git y se colocan en el disco para que puedan usar o modificar.
El área de preparación es un archivo, por lo general contenido en el directorio de Git, que almacena información acerca de lo que va a guardar la próxima vez en la base de datos. A veces se refiere como el "índice", pero también es común referirse a él como el área de preparación.
El flujo de trabajo básico de Git es algo como esto:
- Modifica los archivos en el directorio de trabajo.
- Preparas los archivos, añadiendo pantallazos de ellos a nuestra área de espera.
- Se realice un commit, que toma los archivos que están en el área de espera y almacena esos pantallazos de forma permanente al directorio de Git.